多言語翻訳機が手ごろな値段でてに入るようになった現代。
ニュースもそうあるべき、とのさらに先行く言語翻訳システム開発、
さすがFace book!!
中間点に英語があったとは!!!
世界は知らないことで満ちている!!!!
それを知るのが、私の喜び。そしてそれを共有したいと願うわたしのブログ。
そんなことはどうでもよくて、
さあ、今日もVOAニュース!!
Facebook、100言語に対応した機械翻訳システムを開発
Facebook Develops Machine Translation System for 100 Languages
October 21, 2020
Facebookは、最初に英語に入ることなく、100の言語のうちの任意の2つの間で翻訳することができる初の機械学習モデルを開発しました。
Facebookは、新しい多言語機械翻訳モデルが世界中の20億人以上のユーザーを助けるために作成されたといいます。会社はまだ翻訳システム-M2M-100と呼ばれるもので-をテストしています、そして未来の異なった製品にそれを加えることを望んでいます。
ソーシャルメディアサービスは、このシステムをオープンソース化したと述べていますーーそのコンピュータコードは、他の人がコピーしたり変更したりすることが自由に利用できることを意味します。
アンジェラファン, Facebookの研究助手, 会社のウェブサイトの1つで今週新しい機械翻訳モデルを説明しました. 彼女は開発が”械翻訳の基礎的な仕事”の数年後に進行中の”道しるべ”を提示したのです、と話しています。
ファン氏によると、このモデルは、翻訳プロセスを英語に依存している他の機械学習システムよりも優れた結果が得られるといいます。他のシステムは、英語以外の2つの言語間で翻訳するために中間的なステップとしてーーブリッジのようなものーーとして英語を使用します。
一例として、中国語からフランス語への翻訳が挙げられます。ファン氏は、多くの機械翻訳モデルは、まず中国語から英語に翻訳し、次に英語からフランス語に翻訳することから始めると述べています。これは、”英語のトレーニングデータが最も広く利用可能だからです”と彼女は言います。しかし、このような方法では翻訳にミスが生じる可能性があります。
「我々のモデルは、中国語からフランス語へのデータを直接学習することで、より良い意味を保持することができます」とファン氏は述べています。Facebookは、このシステムは機械翻訳の品質を測定するために使用するデータである広く使用されているシステム英語中心のシステムよりも優れていると述べています。
Facebookはユーザーの約3分の2が英語以外の言語で伝達し合うと言います。同社はすでにFacebookのニュースフィード上で毎日20億の翻訳の平均を行なっています。 しかし、それは多くのユーザーが160以上の言語でコンテンツの膨大な量を公開するという巨大なテストに直面しています。
開発チームは、100言語の75億文対のデータセット上で新しいモデルを訓練しました。さらに、合計2,200の言語の方向性についても訓練を行いました。Facebookによると、これは過去の最高の機械翻訳モデルの10倍の数だといいます。
チームが直面した困難の1つは、広く使われていない言語の組み合わせに対して効果的な機械翻訳システムを開発しようとすることでした。Facebookはこれらを "低リソース言語 "と呼んでいます。新しいモデルを作成するために使用されたデータは、インターネット上で利用可能なコンテンツから収集されました。しかし、低リソース言語に関するインターネット上のデータは限られています。
この問題に対処するために、Facebookは逆翻訳と呼ばれる手法を使ったといいます。この方法では、”合成翻訳”を作成して、リソースの少ない言語での訓練に使用するデータ量を増やすことができます。
今のところ、同社によれば、新しい言語研究の方法を模索しながら、新しいモデルの改良に取り組んでいく予定だといいます。Facebook上で翻訳システムを起動するための日付は設定されていません。
しかし、アンジェラ・ファン氏は、この新システムはFacebookにとって、特に私たちが生きている時代にとって重要な一歩を示すものだと述べています。「機械言語翻訳によって言語の壁を壊すことは、人々を結びつけ、COVID-19に関する権威ある情報を提供し、有害なコンテンツから人々を守るための最も重要な方法の1つです。」と彼女は述べています。
Facebook Develops Machine Translation System for 100 Languages
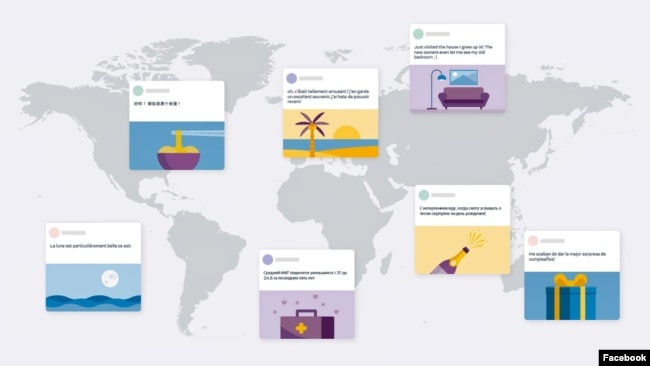 Facebook says it has developed the first machine learning model to translate between 100 languages without having to be translated into English first. (Facebook)
Facebook says it has developed the first machine learning model to translate between 100 languages without having to be translated into English first. (Facebook)
Facebook has developed the first machine learning model that can translate between any two of 100 languages without going into English first.
Facebook says the new multilingual machine translation model was created to help its more than two billion users worldwide. The company is still testing the translation system – which it calls M2M-100 - and hopes to add it to different products in the future.
The social media service says it has made the system open source -- meaning its computer code will be freely available for others to copy or change.
Angela Fan, a research assistant at Facebook, explained the new machine translation model this week on one of the company’s websites. She said its development represented a “milestone” in progress after years of “foundational work in machine translation."
Fan said the model produces better results than other machine learning systems that depend on English to help in the translation process. The other systems use it as an intermediate step -- like a bridge -- to translate between two non-English languages.
One example would be a translation from Chinese to French. Fan noted that many machine translation models begin by translating from Chinese to English first, and then from English to French. This is done “because English training data is the most widely available," she said. But such a method can lead to mistakes in translation.
"Our model directly trains on Chinese to French data to better preserve meaning,” Fan said. Facebook said the system outperformed English-centered systems in a widely used system that uses data to measure the quality of machine translations.
Facebook says about two-thirds of its users communicate in a language other than English. The company already carries out an average of 20 billion translations every day on Facebook’s News Feed. But it faces a huge test with many users publishing massive amounts of content in more than 160 languages.
The development team trained, or directed, the new model on a data set of 7.5 billion sentence pairs for 100 languages. In addition, the system was trained on a total of 2,200 language directions. Facebook said this is 10 times the number on the best machine translation models in the past.
One difficulty the team faced was trying to develop an effective machine translation system for language combinations that are not widely used. Facebook calls these “low-resource languages.” The data used to create the new model was collected from content available on the internet. But there is limited internet data on low-resource languages.
To deal with this problem, Facebook said it used a method called back-translation. This method can create “synthetic translations” to increase the amount of data used to train on low-resource languages.
For now, the company says, it plans to continue exploring new language research methods while working to improve the new model. No date has been set for launching the translation system on Facebook.
But Angela Fan said the new system marks an important step for Facebook, especially for the times we live in. "Breaking language barriers through machine language translation is one of the most important ways to bring people together, provide authoritative information on COVID-19, and keep them safe from harmful content," she said.
_______________________________________________________________
Words in This Story
translate – v. change written or spoken words from one language to another
code – n. a set of rules used to instruct computers how to behave or do things
milestone - n. an event that reaches never before seen levels
intermediate – adj. between two different stages in a process
preserve – v. keep something the same or prevent it from being damaged of destroyed
pair – n. two things that look the same and are used together
content – n. information contained in a piece of writing, a speech, a movie or on the internet
synthetic – adj. not made from substances or in the usual way
authoritative – adj. respected and considered to be accurate