AIによる検索エンジン、その機能とは。
すごい!!の一言です。
新しい検索ツールが機械学習を利用して、何百万もの米国の新聞ページから歴史的な写真を検索する、というのですから。
さあ、今日のVOAニュース、
早速、その機能を見てみましょう!!
新しいAIツールが何百万もの歴史的な新聞ページを検索
New AI Tool Searches Millions of Historical Newspaper Pages
September 30, 2020
新しい検索ツールが機械学習を利用して、何百万もの米国の新聞ページから歴史的な写真を検索します。
米国議会図書館はこのほど、”Newspaper Navigator”と呼ばれるツールの提供を開始しました。このオンライン検索システムは、一般の人が無料で利用できます。
米議会図書館は世界最大の図書館です。米国の創造的な記録の資料を提供しています。この図書館は、米国議会の主要な研究サービスとして機能しています。
新聞ナビゲーターは現在、1900年から1963年までの全米の新聞から1600万ページ以上を検索することができます。
新聞のページは、Chronicling Americaと呼ばれる米国議会図書館の別のプロジェクトのためにデジタル化されました。このツールでは、図書館の1600万ページの新聞を検索することもできます。ページには150万以上の画像が含まれています。
Chronicling Americaシステムは、ユーザーがデジタル化されたイメージとして新聞の全ページを検索して見ることを可能にします。ユーザーはまた、光学式文字認識--OCR--を使用して、キーワードでコレクションを検索することができます。OCRは、デジタルカメラを使用してページ上の印刷された文字を識別して検索したり、テキストを作成したりするツールです。
このため、Chronicling Americaサイトを利用する人は、特定の画像を見つけようとするとき、新聞のページを自分で検索しなければなりませんでした。新しい新聞ナビゲーターツールは、コレクションの中の画像のみのコンテンツに基づいて検索を実行する機能を提供します。
ここで機械学習法の出番です。検索システムは、さまざまな種類の画像を認識するように訓練されています。例えば、写真、地図、マンガ、広告などを区別できるように設計されています。また、類似した画像を識別して検索結果に返すこともできます。
このシステムを作ったのはベンジャミン・リー氏。彼は、米国議会図書館のイノベーター・イン・レジデンス・プログラムのメンバーです。このプログラムは、図書館の膨大な歴史的コレクションを一般の人に見せるための新しい方法を生み出そうと、さまざまな分野の人をスポンサーにするために設立されたものです。
リー氏は、視覚的なコンテンツを識別するために機械学習モデルを訓練し、Chronicling Americaの1,600万ページすべてに渡ってモデルを実行しました。
彼のトレーニングモデルは、Beyond Words と呼ばれる米国議会図書館の別の実験に基づいていました。このプロジェクトでは、第一次世界大戦中の新聞に掲載されている漫画、絵、写真、広告を識別するために、一般の人々を招待しました。
リー氏は、Beyond Wordsの実験を知ってから、その情報を機械学習ツールの動力源として利用できる可能性を感じたと言います。「私は、この識別されたビジュアルコンテンツが、Chronicling Americaの1,600万ページ全体のビジュアルコンテンツの宝箱を開ける鍵になるのではないかと考え始めました。」
新聞ナビゲーターは、他の検索エンジンと同じように動作します。ユーザーは”キーワード”ボックスに検索語を入力します。また、検索結果を場所や日付で限定することもできます。
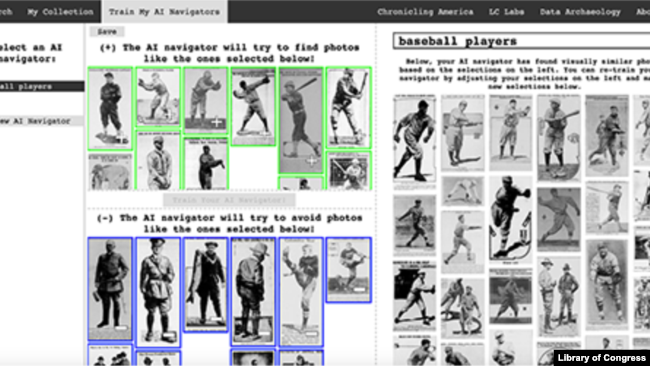
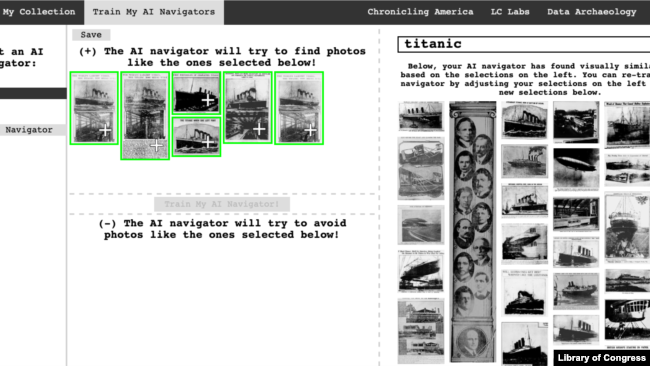
しかし、このシステムの中で最も強力なツールの一つは、視覚的な類似性によって画像を検索する機能です。このツールのユーザーは、画像を個人の”コレクション”に保存することができます。そして、それらの画像をもとに、図書館の全コレクションの中から視覚的に類似した画像を探すことができるのです。
このシステムは、ユーザーが個々の検索のために機械学習ツールを”再学習”することもできます。これは、検索結果の画像を調べることによって行われます。見つかった画像が目的の結果に似ているか似ていないかを選択することで、ユーザーはシステムの検索性能を向上させるために”再訓練”を行っています。
新聞ナビゲーターのデモを見ることで、ユーザーはツールの詳細やさまざまな検索方法を知ることができます。制作者は、このツールが歴史家、記者、教育者、専門の研究者、または新聞を通して米国の歴史を学ぶことに興味のある人に役立つことを願っています。
米議会図書館は、Newspaper NavigatorとChronicling Americaに含まれるすべての画像はパブリックドメインであり、人々が自由に好きなように使用できることを意味と期しています。
New AI Tool Searches Millions of Historical Newspaper Pages
 Search results from millions of American newspaper pages as generated by the Newspaper Navigator tool. (Newspaper Navigator, Library of Congress)
Search results from millions of American newspaper pages as generated by the Newspaper Navigator tool. (Newspaper Navigator, Library of Congress)
A new search tool uses machine learning to search millions of U.S. newspaper pages for historical pictures.
The U.S. Library of Congress recently launched the tool, called Newspaper Navigator. The online search system is available for free to the public.
The Library of Congress is the world’s largest library. It offers materials from the creative record of the United States. The library serves as the main research service for the U.S. Congress.
Newspaper Navigator currently permits users to search more than 16 million pages from newspapers across the country, from 1900 to 1963.
The newspaper pages were digitized for another Library of Congress project, called Chronicling America. This tool also permits searches across the library’s 16 million newspaper pages. The pages contain more than 1.5 million images.
The Chronicling America system permits users to find and look at full newspaper pages as digitized images. Users can also search the collection by keyword, using optical character recognition -- OCR. OCR is a tool that uses digital cameras to identify printed characters on a page for searches or to produce text.
This meant that people using the Chronicling America site had to search through newspaper pages themselves when trying to find specific images. The new Newspaper Navigator tool offers the ability to carry out searches based on image-only content in the collection.
This is where the machine-learning methods come in. The search system was trained to recognize different kinds of images. For example, it was designed to tell the difference between photos, maps, comics, advertisements, etc. It can also identify similar images and return these in search results.
Benjamin Lee created the system. He is a member of the Library of Congress’ Innovator in Residence Program. The program was established to sponsor people from different fields to create new ways to present the library’s huge historical collections to the public.

Lee trained a machine-learning model to identify the visual content and then ran the model over all 16 million pages in Chronicling America.
His training model was based on another Library of Congress experiment called Beyond Words. That project invited members of the public to help identify cartoons, drawings, pictures and advertisements in newspapers during World War I.
Lee said that after he learned of the Beyond Words experiment, he saw a great possibility to use that information to power his machine-learning tool. “I began to wonder whether this identified visual content was the key to throwing open the treasure chest of visual content, throughout all 16 million pages in Chronicling America.”
Newspaper Navigator works like other search engines. Users enter a search term in the “keyword” box. They can also choose to limit search results by location, as well as by date.
But one of the most powerful tools in the system is the ability to search images by visual similarity. Users of the tool can save images to a personal “collection.” They can then use those images as a basis for finding other visually similar images across the library’s full collection.
The system even permits users to “retrain” the machine learning tool for individual searches. This is done by examining the images that the search returns. By selecting whether images found were similar or not similar to the desired result, the user is “retraining” the system to improve its search performance.
A demonstration of the Newspaper Navigator is available to help users learn more about the tool and how to carry out different searches. The creators hope the tool can be useful for historians, reporters, educators, professional researchers or anyone interested in learning about U.S. history through newspapers.
The Library of Congress notes that all images included in Newspaper Navigator and Chronicling America are in the public domain, meaning people are free to use them as they wish.
________________________________________________________________
Words in This Story
page – n. one part of a website
digitize – v. to put information into the form or a series of numbers, usually so that it can be understood by a computer
character – n. a letter, number or other mark or sign used in writing or printing
comics – n. a series of pictures that tell a story
content – n. information contained in a piece of writing, a speech, a movie or on the internet
visual – adj. related to seeing
sponsor – v. to pay for someone to do something or for something to happen
location – n. place where something takes place